Evaluating Your LLM in Three Simple Steps
Evaluation is a critical step in the development cycle of large language models (LLMs). Evaluation enables you to select the right LLM at inference and point your LLM to a north star when tuning it. Evaluation needs to be rigorous in order to be reliable and automated to be scalable.
In this blog post, we will show you how to build a reliable and automated evaluation pipeline for the top open LLMs in a few simple steps using our SDK. You can find all the code here.
This evaluation is actually live in our LLM Photographic Memory Evaluation Suite, which quantifies an LLM's ability to recall important facts and figures with photographic memory, e.g. quarterly revenue numbers.
Step 1: Installation
First, clone the repository:
git clone git@github.com:lamini-ai/lamini-earnings-sdk.git
Next, get your Lamini API key from here. If it’s your first time using Lamini, log in to create a free account. Add your key to your environment variables by running in your terminal:
export LAMINI_API_KEY="<YOUR-LAMINI-API-KEY>"
You can also authenticate via Lamini’s Python library.
Install the Python library:
pip install lamini
Now, let's run Llama 3:
import lamini
lamini.api_key = "<YOUR-LAMINI-API-KEY>"
llm = lamini.Lamini(model_name="meta-llama/Meta-Llama-3-8B-Instruct")
print(llm.generate("How are you?"))
You can run this script to set up a clean environment in Docker:
./llama3.sh
Step 2: Dataset Preparation
To evaluate the basic performance of multiple base models on your data, you need two types of datasets: a golden test set and an extended dataset.
1. Golden Test Set: Write 20-100 examples of prompts/responses.
- Ensure they are representative of the diversity of prompts that you expect users to use your LLM.
- Sometimes getting a business, ops, or product person to play with an LLM and sit alongside devs to create this can be helpful.
- While more examples take more effort to create, the reliability of the evaluation is directly proportional to how much effort is put here.
- It can be helpful to include key prompt/response pairs that you do not want the LLM to regress on and make sure it gets right.
- It can be helpful to include some borderline cases that the LLM gets incorrect now, but you really need it get correctly, so you are measuring what you expect to improve on.
2. Extended Dataset: Use Lamini’s Data Generation pipeline to generate more prompt/response pairs from a pipeline of LLMs, based on your golden test set.
- In this example, the prompt is a question and the response is an answer. But you can adapt this pipeline to extend any type of prompt/response, by just editing the prompt.
- It can be helpful to prompt engineer the pipeline and see whether the extended pairs are representative.
- One important aspect of this is that this runs fast, so you can generate more pairs and be able to iterate on the prompts for the LLM pipeline.
- Having more pairs that are inspired by your golden test set automates covering more area in your full evaluation set.
In this SDK, we prepared golden_test_set.jsonl with 99 examples and then used the data pipelines to generate over 3,000 Q&A pairs in earnings_call.jsonl.
If you want to use your own data, please use earnings_call_dataset.py as a template, add your dataset, and define your data schema properly.
Step 3: Run Evaluation and Compare Models
In your terminal, navigate to the SDK folder:
cd lamini-earnings-sdk
Run the evaluation script:
./02_eval/scripts/eval.sh
The default model is Llama 3. To change the model, update the model name in eval.py:
parser.add_argument(
"--model",
type=str,
default="meta-llama/Meta-Llama-3-8B-Instruct",
help="The name of the model to evaluate",
)
We use Hugging Face which has a longer name for each model. For example:
- Llama 3: meta-llama/Meta-Llama-3-8B-Instruct
- Mistral 2: mistralai/Mistral-7B-Instruct-v0.2
- Phi 3: microsoft/Phi-3-mini-4k-instruct
You can also change the number of evaluation examples:
parser.add_argument(
"--max-examples",
type=int,
default=100,
help="The max number of examples to evaluate",
)
Evaluation Results
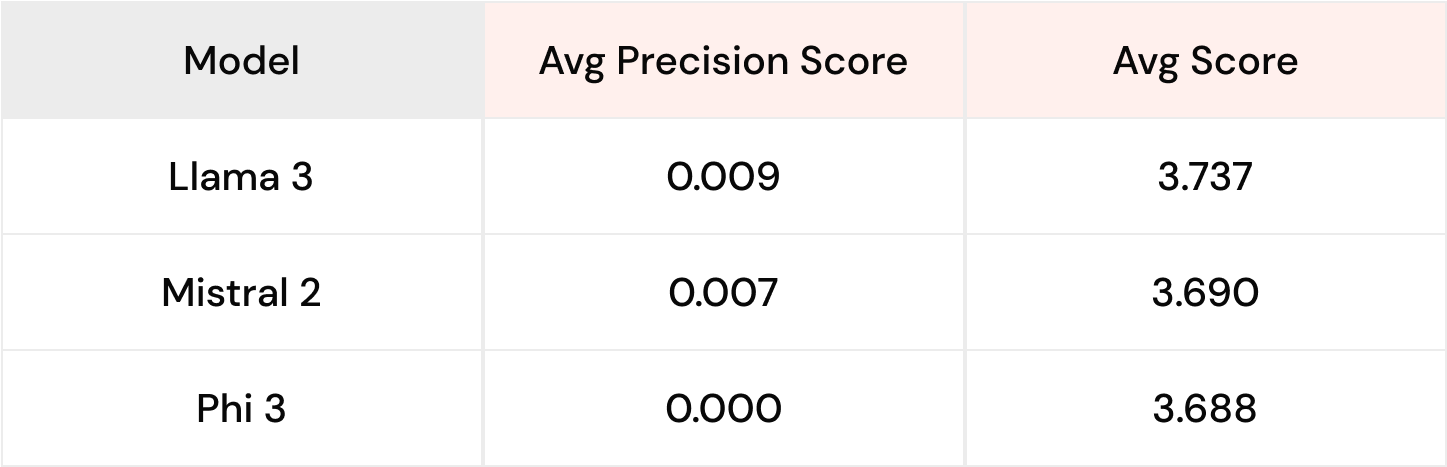
Llama 3 vs. Mistral 2 vs. Phi 3 (1000 examples)
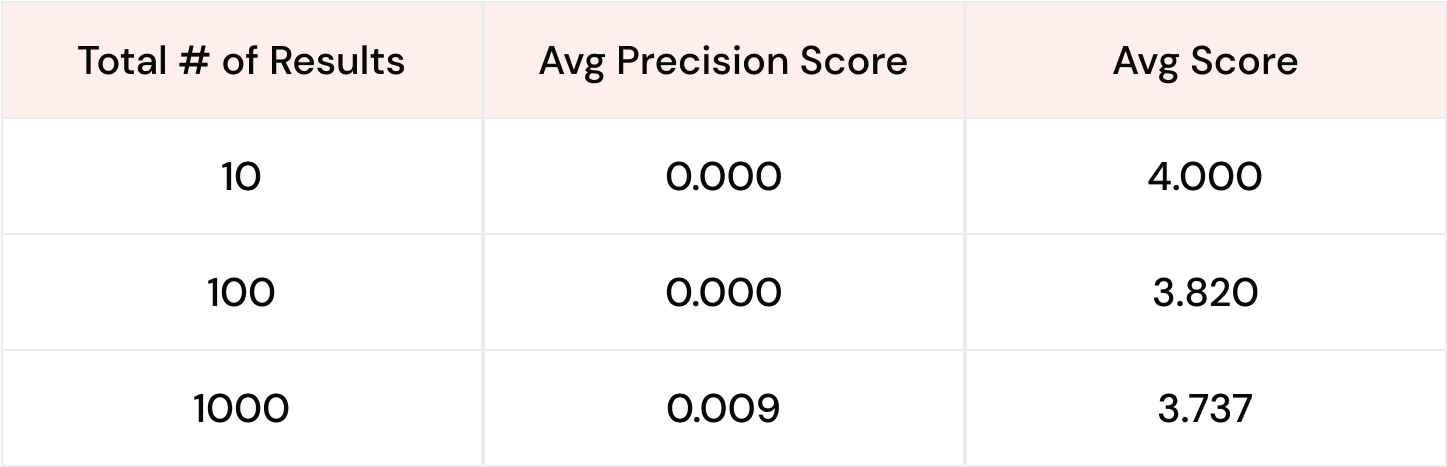
10 examples, 100 examples, 1000 examples for Llama 3
Happy evaluating! Let us know which model works best for your use cases!