LLM inference & tuning
for Enterprise.
Super fast. Extremely secure.

Performance
Improve accuracy, dramatically reduce hallucinations
- Guaranteed structured output with optimized JSON decoding
- Photographic-memory through retrieval-augmented finetuning
- DPO training with human preferences
- Integrated RAG-Finetuning framework
- Evaluation frameworks for tuned models
Time to Market
Accelerate development, with no rate limits
- Highly parallelized inference for large batch inference
- Parameter-efficient finetuning that scales to millions of production adapters
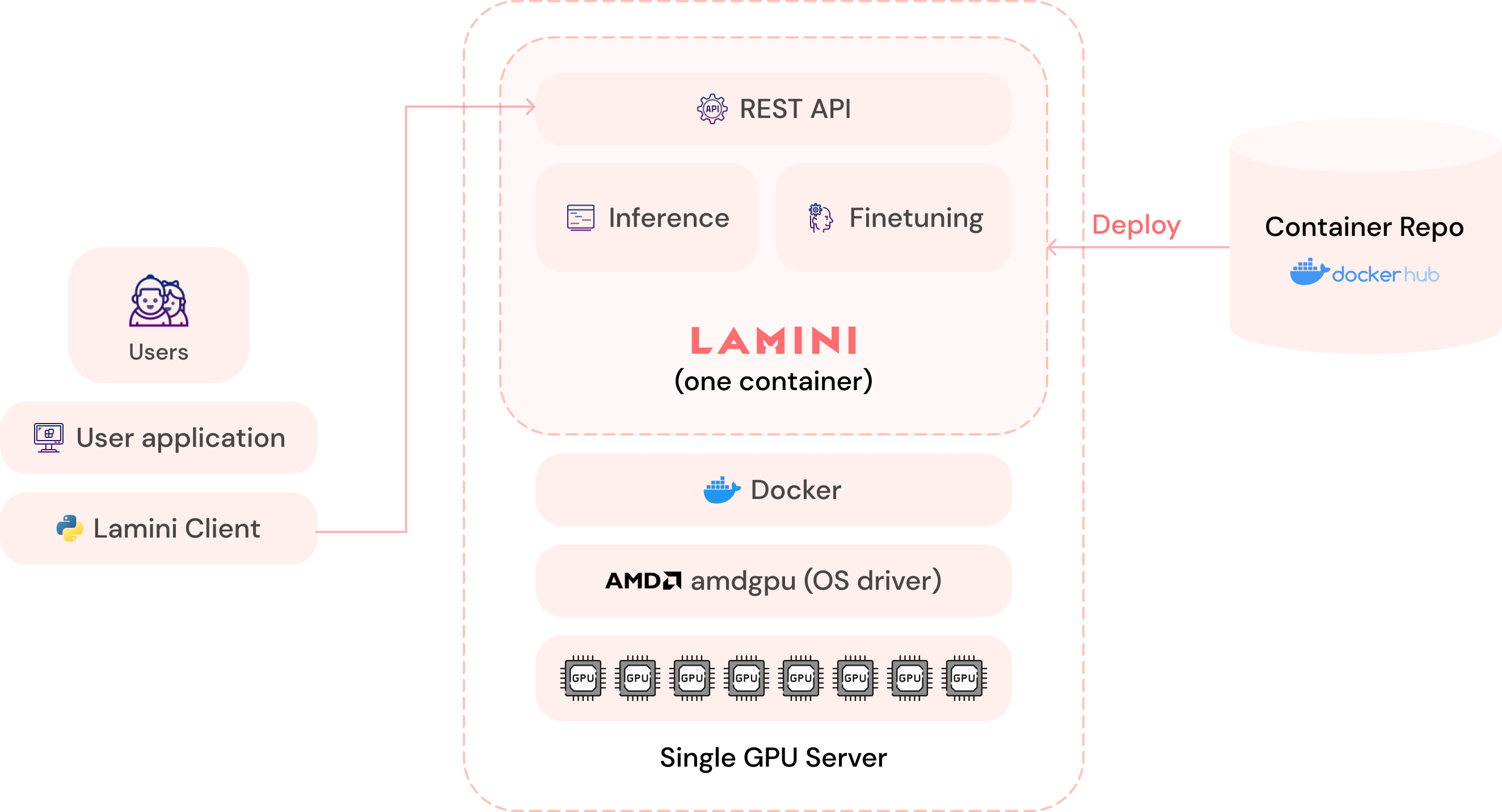
- Infrastructure-agnostic: hybrid cloud VPCs, on-premise airgapped clusters, Nvidia or AMD GPUs.
- Scalable costs with ROI, e.g. inference on 1 million docs: $80 on Lamini vs. $50.000 on Claude 3
Our Leadership

Sharon Zhou
Co-Founder & CEO


- Stanford CS Faculty in Generative AI
- Stanford CS PhD in Generative AI (Andrew Ng)
- MIT Technology Review 35 Under 35, for award-winning research in generative AI
- Created largest Coursera courses (Generative AI)
- Google Product Manager
- Harvard Classics & CS

Greg Diamos
Co-Founder & CTO
- MLPerf Co-founder, industry standard for ML perf
- Landing AI Engineering Head
- Baidu Head of SVAIL, deployed LLM to 1+ billion users; led 125+ engineers
- 14,000 citations: AI scaling laws, Tensor Cores
- NVIDIA, CUDA architect - as early as 2008
- Georgia Tech PhD in Computer Engineering
Blogs
View all blogs








Talks
View all talks